Update: 20/03/26
https://openai.com/index/openai-to-acquire-astral/
... 😔
What a time to be alive and to be a Python dev. I don’t know about you, but at work we’ve been going heavy on Astral’s tooling ecosystem, using uv, ruff and (hopefully once it’s out of beta at the time of writing this) ty. Not only is their tooling just fast, but it’s also really pleasant to work with.
I really wanted to deep dive into a single aspect of package managers and one area that interested me was the dependency resolution strategies that they use. For this post, I’m going to be diving deep into uv’s dependency solver and comparing it to pip’s resolver, the traditional Python package manager.
Keep in mind, package managers are a lot more than just a resolver. They need to also deal with things like IO, caching, serialisation/deserialisation etc. What’s more impressive is that they also need to deal with:
- Different versions of Python
- Operating systems a user could be using
- Versioning, in particular PEP440 standards
I’ve linked some additional resources at the end of this write-up that covers each of these in more detail.
Dependency hell
Our resolver needs to do two things:
- Figure out if we can satisfy all requirements in our pyproject.toml/requirements.txt
- Build a dependency graph with concrete dependency and transitive dependency versions
Now, this problem becomes exponentially more complex as the number of packages and their version ranges interact. e.g. if package A has 10 versions and B has 10 versions, you’re already checking 100 combinations before subdependencies fan out further.
From a mathematical standpoint, dependency resolution is generally considered NP-Hard. The number of possible version combinations grows faster than any polynomial as the dependency tree expands (I’m not even going to pretend that I can explain this clearly so here is a nice post to describe in depth what it means). In essence, it means it’s extremely difficult to solve efficiently, and no fast algorithm exists to find a perfect answer.
Regardless, many package managers, even outside Python, have come up with their own elegant solutions which we all use to this day. Let’s start to build out a really simple version and slowly introduce new techniques which align with how uv solves this problem.
Plumbing
At the cost of real-world complexity (network requests, auth, caching, platform metadata), I used a mock index (a local JSON file) to sidestep dealing with network requests to fetch actual package metadata. I also created a simple set of models that represent the packages in this mock dependency graph. The base building block is a Constraint, which represents a single requirement, like requests >= 2.0, where the operator tells the resolver what’s acceptable. Packages are made up of multiple versions, each with their own set of constraints. Requirements are also read in as constraints, parsed from a requirements.txt file.
Also note that the mock dependency graph is ordered from newest to oldest version
@dataclass
class Constraint:
package_name: str
operator: str
version: str
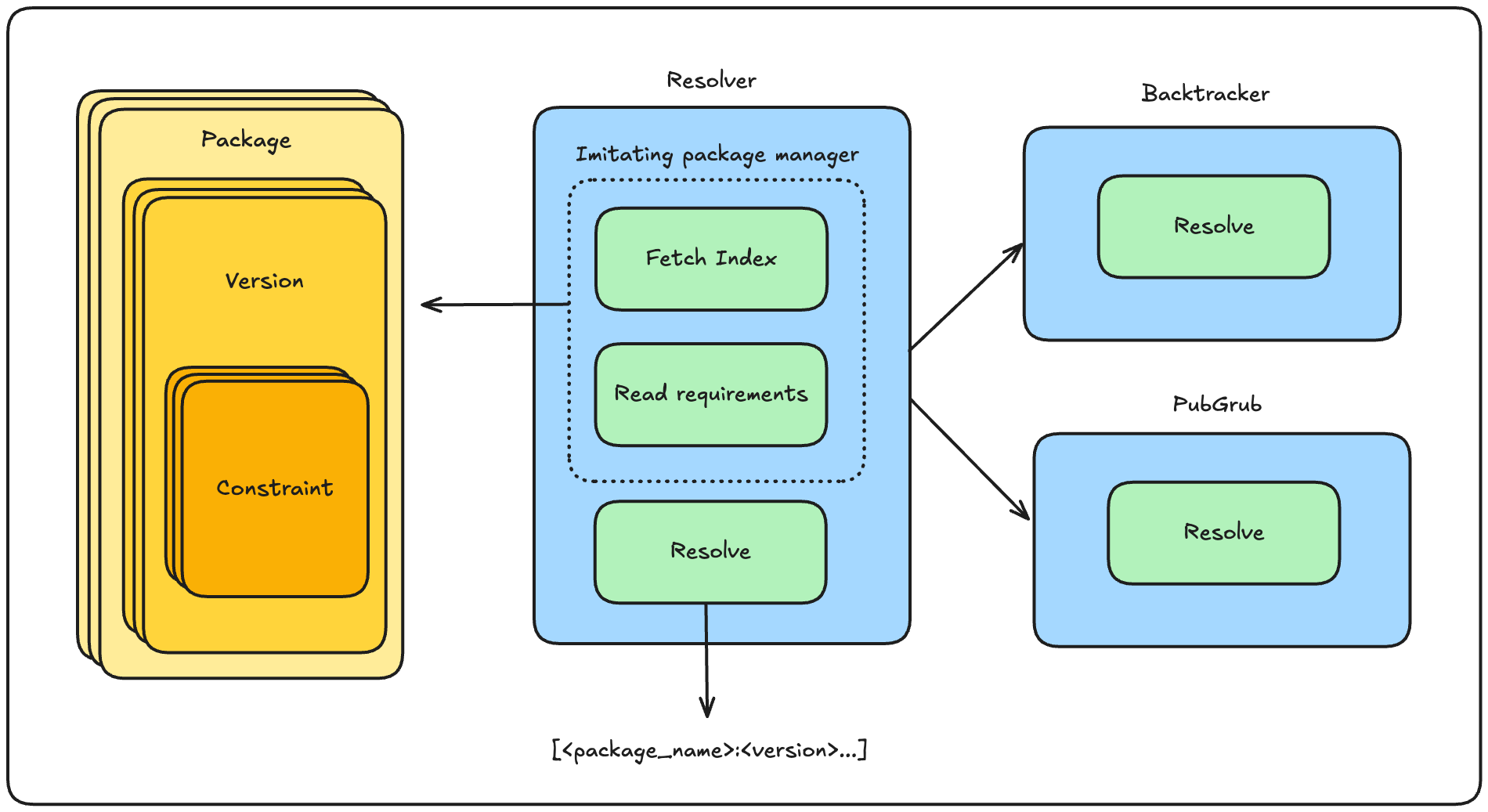
The last thing we need is an abstract class (Resolver) that provides shared behaviour (lock file writing, reading dependencies). Resolution logic lives in a concrete subclass, which gives us an apples-to-apples comparison between different resolver solutions.
The full implementation is available here if you want to follow along. With the scaffolding in place, let’s start with the simplest possible resolver: backtracking.
Backtracking
This is probably the most naive approach to dependency resolution, and is roughly what pip used. In our implementation, this is a recursive depth-first search. The algorithm builds a solutions map on the fly, which becomes the final solved list if all the constraints are satisfied.
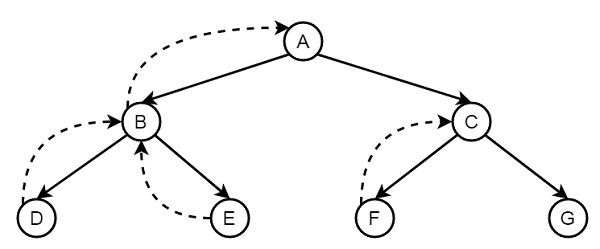
Backtracking illustration from https://www.geeksforgeeks.org/dsa/backtracking-meaning-in-dsa/
Here’s the algorithm in a nutshell:
1. Pick the next requirement from our list
2. If the package is already in the solution, check if the pinned version satisfies this constraint
- Yes → skip to the next requirement
- No → return failure (propagates up to the caller to try a different version)
3. Otherwise, try each version of that package newest-first
4. If a version satisfies the constraint, add it to the solution and recurse with the remaining requirements plus its transitive dependencies
5. If the recursive call fails, remove it from the solution and try the next version
6. If no version works, return failure so the caller can backtrack
The mock graph I used has a purposeful conflict near the bottom of the dependency tree. Here’s the trace:
trying auth version 2.0.0
solving json-lib for version 2.0.0
json-lib in solution with version 2.0.0
json-lib with version 2.0.0 not satisfied!
auth version 2.0.0 not satisfied
trying auth version 1.0.0
solving json-lib for version 2.0.0
json-lib in solution with version 2.0.0
json-lib with version 2.0.0 not satisfied!
auth version 1.0.0 not satisfied
json-lib version 2.0.0 not satisfied
trying json-lib version 1.5.0
trying json-lib version 1.0.0
database version 2.0.0 not satisfied
trying database version 1.0.0 ← backtracks here
...
trying auth version 2.0.0 ← hits the exact same auth failure again
json-lib with version 2.0.0 not satisfied!
auth version 2.0.0 not satisfied
trying auth version 1.0.0
json-lib with version 2.0.0 not satisfied!
auth version 1.0.0 not satisfied
Both auth versions fail for the exact same reason and its that json-lib is already pinned to 2.0.0 and neither can satisfy it. After backtracking to try a different database version, it rediscovers the same failure from scratch. Backtracking finds the right answer, but it’s slow because it doesn’t learn why something failed and just blindly tries the next option.
Note: Backjumping was actually added in pip 25.1 (2025). Instead of backtracking one step at a time, it skips past packages not involved in the conflict. This is closer to what you’d see in conflict-driven approaches, which we will explore next.
PubGrub
PubGrub was first developed for the Dart language, and the resolver strategy became the foundation for many package managers going forward (Cargo, Poetry, uv, Swift Package Manager). The essence of this resolver, compared to pure backtracking, is that it learns from conflicts.
This is why when we use uv, we see such nice conflict messages when a package can’t be resolved.
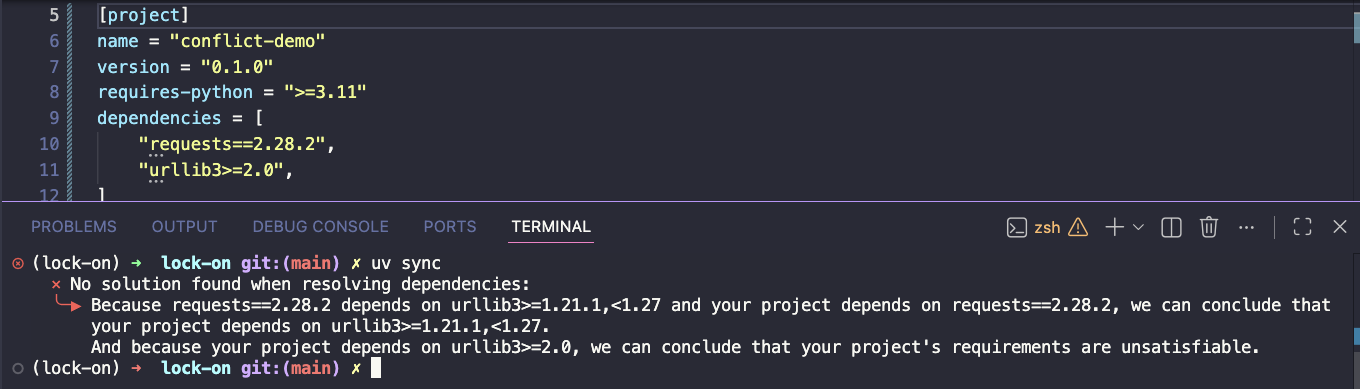
While it’s difficult to implement the full PubGrub solution, for this toy example I implemented a simplified approach using unit propagation, a technique that also underpins DPLL and CDCL-based solvers, which introduces some of this conflict driven learning into the existing backtracking.
DPLL’s key additions include:
- Unit propagation - if a constraint forces a specific choice (only one version is viable), make that choice immediately without searching. Prunes the search space before you even start backtracking.
- Conflict-driven learning - when you hit a contradiction, record why it happened as a clause, so you don’t repeat the same mistake.
For my implementation I only introduced Unit Propagation (UP) just to highlight the more pro-active nature of conflict driven learning. Here’s the algorithm:
1. Run unit propagation — group constraints by package and find forced assignments in a fixpoint loop
2. If UP finds a conflict → return immediately (no branching needed)
3. Pick the next unsatisfied requirement
4. Try a version of that package
5. If it conflicts with what's already in the solution, try the next version
6. If no version works, backtrack to the previous requirement
7. If it works, add it to the solution and recurse
8. On exit (success or failure), roll back all forced assignments from UP
The same graph with unit propagation enabled:
unit propagation forced web-app=1.0.0 ← only one version, pinned immediately
unit propagation resolved 1 package(s): {'web-app': '1.0.0'}
...
trying api version 2.0.0
unit propagation forced json-lib=2.0.0 ← UP narrows json-lib before branching
unit propagation resolved 1 package(s): {'json-lib': '2.0.0'}
...
trying auth version 2.0.0
unit propagation forced crypto=2.0.0 ← UP forces crypto before exploring auth's subtree
unit propagation resolved 1 package(s): {'crypto': '2.0.0'}
json-lib with version 2.0.0 not satisfied!
auth version 2.0.0 not satisfied
...
UP fires before each branch, immediately collapsing packages where only one candidate is viable. It still hits the json-lib conflict but you can see it constraining the search space ahead of time rather than discovering failures reactively. On a larger graph with more forced assignments, the savings compound significantly.
Key differences: proactive vs reactive
- Backtracking is purely reactive, it assigns a version, recurses, hits a conflict deep in the tree, then unwinds. It discovers problems late.
- DPLL with unit propagation is proactive. Before branching, it asks “are there any packages where I have no choice?” and forces those assignments immediately. This prunes entire subtrees before they’re ever explored.
- UP doesn’t eliminate branching entirely, when 2+ candidates exist, you still branch and backtrack. DPLL just reduces how much branching is needed.
- PubGrub extends this further with an implication graph, conflict analysis, and non-chronological backjumping which allows it to learn from conflicts permanently.
So why is uv so much faster than pip?
Other than the fact its written in Rust with its more efficient memory management, a few compounding reasons. The resolver is the most relevant given what we just built, but IO handling is a big one too.
The resolver
The three components that make this work: grouping all constraints per package, unit propagation (forcing when only one candidate remains), and a fixpoint loop (one forced assignment can trigger another). uv’s PubGrub-based resolver builds on all three, closer to the DPLL approach we explored which means it fails fast on conflicts rather than blindly retrying.
pip uses resolvelib under the hood, a backtracking resolver. As we saw, this can get expensive fast, and pip’s own issue tracker has documented the consequences for years:
- ResolutionTooDeep — pip recommends uv as a workaround
- resolver takes 1-2 hours for large requirements files
- O(n²) complexity in backtracking
This alone makes a significant difference for large dependency trees.
Parallelism
uv fetches package metadata and wheels in parallel (also does a lot more). pip’s parallel download issue has been open since 2013. This is particularly painful on a cold cache where everything needs to be fetched from the network.
Closing thoughts
A colleague and I were talking recently about software in the industry, and they made a point that stuck with me which kind of inspired me following through on this project. The things we build will always get replaced. New standards emerge, better algorithms get published, the ecosystem shifts and eventually what we made is re-written or thrown away.
pip is a good example of that. The backtracking resolver wasn’t bad engineering, it worked for years and served an enormous ecosystem. It just outlived its context. The irony is that uv’s existence owes as much to updated PEP standards as it does to better algorithms. The rewrite had to wait for the ground to shift first.
What I find interesting is that this is very different from, say, the games industry. Pac-Man is still Pac-Man. The code that ran it in 1980 doesn’t need to care about dependency graphs or parallelism or security standards. Maybe if I want my code to outlive me, i’m in the wrong industry ;)
Resources
There is actually a lot of good stuff out there which goes into a lot of this in depth:
- Charlie Marsh’s Jane Street talk — goes deeper into why uv is so fast
- Andrew Nesbitt’s deep dive — how updated PEP standards are one of the main drivers behind uv’s existence
- Dependency resolution methods comparison — Nesbitt’s follow-up post
- PubGrub explained — the original PubGrub write-up